RCoT
In the last week I integrated RCoT into the Because module, and Roger also finished his work on the traditional probability method on conditional probability. Then it is time to compare the performance.
RCoT vs Prob (Traditional Probability Method)
I run the experiments on two version of test datasets based on the original datasets. The first one is just the original one. In the second one I add more non-linear relationship to simple cases and remove non-linear relationship from the complex case.
I tried different value of Power, which is the parameter for Prob, and used default setting for RCoT, since from the experiments last week the results won't get improved if I increase the number of Fourier Features.
The results showed that:
- For Prob method, increasing Power won't change the results for whether a relation is dependent, it only improves a little for the margin between dependent and independent cases, and it increases running time linearly.
- The results for RCoT is better and more accurate than Prob in most cases, the margin is also larger.
- The running time for RCoT is similar to the running time for Prob when setting Power to 1, so basically Prob is always slower than RCoT.
Since RCoT has showed the better performance on both accuracy and running time, we have set the default dependent method to RCoT.
Downward Compatibility for Lower Version of Python
In the original implementation of lgb4 algorithm, it used math.comb function to calculate the number of combinations. However, it is only supported with Python 3.8 or higher version.
Therefore, I did a modification to it to support lower version of Python.
LiNGAM
Non-Gaussian Problem
It haunts me and Roger a long time why LiNGAM won't work on normal distribution, and in this week I tried to look into it and gave a reasonable answer to that problem from mathematical proof.
The basic idea is that:
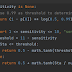
- We only consider the exact case in LiNGAM, which means the relation between all variables should be linear. And in this proof we only consider two variables where one causes another in linear relation, like y=w*x+noise().
- Intuitively we think if we run linear regression on x with variable y, the coefficient would be 1/w, but actually we can prove that the coefficient should be w/(1+w^2).
- Now we can explicitly write out the residual and y, we can prove that residual and y are independent if and only if the noise for both x and y are from normal distribution.
Develop New Direct Test Program and Data Model
I developed a new direct test program this week, which supports many runs with the same method at one execution. Each run will generate a new dataset based on the model provided. In the end the program will calculate the mean results for both forward and backward directions and the margin between them. In our expectation, the results for forward direction should be around 0.5 and the results for backward direction should be close to 0. A better method should have larger margin between them.
The new data model are shown below:

Basically we contained test cases:
- linear relation with normal and non-normal noise
- lot kinds of non-linear relation
- noise dependent on variable
- reverse version of relation
- linear and non-linear combination of multiple variables
Experiment on Different Regression Methods
The different methods tested and their running time table are below:

I also run all methods on 1000 samples with 10 runs to see the accuracy. The conclusions are:
- LinearRegression or any kinds of linear model are totally limited on linear relations, which is expectable. Though they have the fastest speed, it is very hard to apply it in practice due to their limitations.
- The other non-linear regression model share very similar results in experiments. They made mistakes on (N, N3) pair, where they all can not fit well due to it extreme value around 0. They made mistakes on (M, M4), which is expectable since now the noise are dependent with M. (IVB, IVA) is incorrect since the noises are normal. The results for (M, M6) is reversed which is exactly what we expected. The only difference is on (EXP, EXP5), which is complex and some model can give correct results.
- The running time varies a lot. Overall, I think Ridge Regression with Random Fourier Feature has the best performance on speed and can correctly test the results as expected.
Non-linear Regression
In the LiNGAM algorithm, when we want to extend the algorithm to non-linear relation, we must use non-linear regression methods. In the future work on using machine learning to estimate conditional expectation value, non-linear regression is also required. Therefore, it may be better to understand all non-linear model, how they learn from data, what kind of property they have, in order to choose the better one from them.
Therefore, I will start to learn the basic idea of them, and take some notes here.
Kernel Ridge Regression
KRR (Kernel Ridge Regression), just like its name, combines both kernel function and ridge regression. It first uses kernel function to map the original data to a feature space, then uses ridge regression to learn a linear function with L2 penalty. When we use non-linear kernels, we can get the non-linear function in the original space.
So in fact the KRR is very similar to SVR (Support Vector Regression). The only difference would be the loss function. KRR uses traditional linear loss, least squired error, while SVR uses an e-insensitive loss, which ignore the cases where the error is less than a threshold e.
Therefore, the KRR would train faster than SVR, while SVR will predict faster since it only use part of training samples to predict. (The KRR implemented in sklearn and in rff implementation are different, which may be the reason for the different running time.)
Support Vector Regression
The property of SVR is that it ignores the cases that have the prediction error less than a threshold e, and only try to fit on the hard cases.
Plan for Next Week
- Keep working on LiNGAM to compare non-linear method and its boundary.
- Start with the machine learning method on estimation of conditional expectation.


No comments:
Post a Comment