1 Sensitive Feature in RCoT
The need for adding a parameter sensitive into RCoT algorithm is that, for data from reality, the variables always shows some degree of dependence, while the original RCoT algorithm is too sensitive to provide useful information, since it will regard all relations between variables as dependence.
Since the original result p-value goes to 0 when it detects dependence, which makes it impossible to modify it simply by adjusting the threshold, we would need to find another value to make the decision. The new value we use is Sta inside the RCoT algorithm, which is the number of samples multiplies the norm of covariance matrix of two variables.
1.1 Sta Property
Since we need a value which is unrelated with the sample sizes and the number of features, we need to adjust for original Sta to stabilize it on any situations, so that it can represents the degree of dependence between variables. Through experiments, we currently use Sta/(number_of_features**2), which is stable for different number of samples and features. It turns out it is still relevant with the number of conditions, where more conditions will result in smaller value.
Frankly speaking, using Sta does not have theoretical support, the whole purpose of it is to decrease the sensitivity of the original RCoT algorithm.
1.2 Implementation
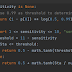
Aside from calculate the new value Sta, we also need to adjust the output for it with new parameter sensitivity. The sensitivity decides the threshold for Sta about whether two variables are dependent. We also use tanh to translate the results into range [0, 1].

2 Conditional Expectation with ML
2.1 Implementation
Since the random forest shows best performance, we now use it as our ML method to calculate expectation. For implementation, we also use parameter power to determine the number of trees of the forest. Larger power corresponds to more trees, which is consistent with the fact about power that larger power will have longer running time while provides more accurate results.
When test on it, some interesting fact shows that when conditioning on one variable, random forest's performance is poor compare with probability method, while conditioning on more than one variables, the performance gets better and shows large improvement over probability method. When conditioning on only one variable, we may need to use other ML methods or use D or J-Prob.
3 Plan for Next Week
- Merge the implementation into Because module
- Prepare for presentation and poster


No comments:
Post a Comment