RCoT algorithm
Learning RCoT algorithm
Continue the task from last week, I finished reading RCoT and RIT paper to have a rough understanding of the algorithm. On Tuesday, Roger also gave me a lecture on RKHS and RCoT, which built an intuitive understanding of these concepts. Though the mathematical proof is still a little difficult for me to understand, the whole process began to make sense to me.
I also learned RCoT algorithm by using debug mode to read the code, which is very useful to understand what the algorithm actually done.
Integrate RCoT algorithm
After the learning of the algorithm, I integrated the code into the Because module and completed the test program for RCoT.


It is easy to change method between traditional probability method and RCoT algorithm. There are something should be noted:
- I fixed a bug in RCoT algorithm, which just uses the first variable in the list of conditional variables.
- I modified function normalize in normalize.py, making it more clear and no need to do extra matrix transpose after normalization.
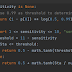
- I changed one line in RCoT algorithm from L = sc.cholesky((Czz + (np.eye(num_f) * 1e-10)), lower=True) to L = sc.cholesky((Czz + (np.eye(num_f) * 1e-6)), lower=True) to avoid error from scipy saying that Czz is not positive semi-definite and is unable to decompose.
- I changed the default value for parameter num_f (Number of features for conditioning set) from 5 to 100, which is the same as in the original R code. This modification improves the algorithm accuracy while does not increase the running time much.
- I choose .99 as the threshold to determine whether two variables are dependent.
Experiments with RCoT algorithm
Some experiments' results are recorded below (Right now in this doc I use .95 as threshold for RCoT, I haven't added new records since meeting in Thursday):
https://docs.google.com/document/d/12C91ALhd9XIxHtONafTw8MlbwRTQdfrrYWMOIZIA75E/edit?usp=sharing
After meeting in Thursday, I did a lot extra experiments, and there are something should be noted from experiments:
- I found the original R code and run the RCoT algorithm on the same dataset using two implementations. Since the algorithm has randomness, and the same random seed does not provide the same results in both R and Python, it is impossible to get the exactly same results. Therefore, I run the algorithm on the same quest like dependence(A, C, [B, D]) multiple times in both R and Python to compare the results. It turns out that the two implementations match and there are no big difference between them. Since p-value itself is a random variable, I would say the two implementations provide the same results.
- After I change the num_f from 5 to 100, the RCoT algorithm can now easily detects dependence and independence correctly when I use simple linear relations. After generating data using complex non-linear relations, the algorithm may give wrong results especially on example like dependence(A, C, [B, D]) and dependence(B, D, [A, C]). Since the original R code also makes mistake on these examples, I think these examples are true difficult examples for RCoT algorithm.
- The randomness in RCoT algorithm is very strong. Since p-value is from uniform distribution when NULL hypothesis is correct, and the random nature in RCoT algorithm, sometimes it will provide incorrect results or subtle results (around 0.5), and the results from different runs can vary a lot.
- From the experiments, setting threshold to .99 and using formula (1-p) ** log(0.5, 0.99) to translate the results always provide satisfied results. When given strong dependent pair of variables, the RCoT algorithm can always get result of 0, or less than 0.01. And for independence pairs, the result will vary from 0 to 1. When using this formula, result p-value in [0.05, 1] will be turned into almost 0, and p-value in [0, 0.001] will be turned into almost 1. Examples between [0.001, 0.05] can be seen as subtle case, which can be taken on extra test if needed.
LPB and Kolmagarov-Smirnov
After experiments on RCoT, I also looked into LPB code and learned what this algorithm is trying to achieve. I also learned Kolmagarov-Smirnov, which is used in the original probability method.
Other Stuff
I spent some time finishing company course of Harassment Prevention Training and CDA-RSG Cyber Defense Onboarding Curriculum.
Plan for next week
- After Roger fix the problem in probability method, I will run a through experiments on both methods and compare them.
- Evaluate LPB as an alternative to Kolmagarov-Smirnov in our current independence test.
- Understand DirectLiNGAM algorithm, and our Causal Direction Conjecture.


No comments:
Post a Comment